

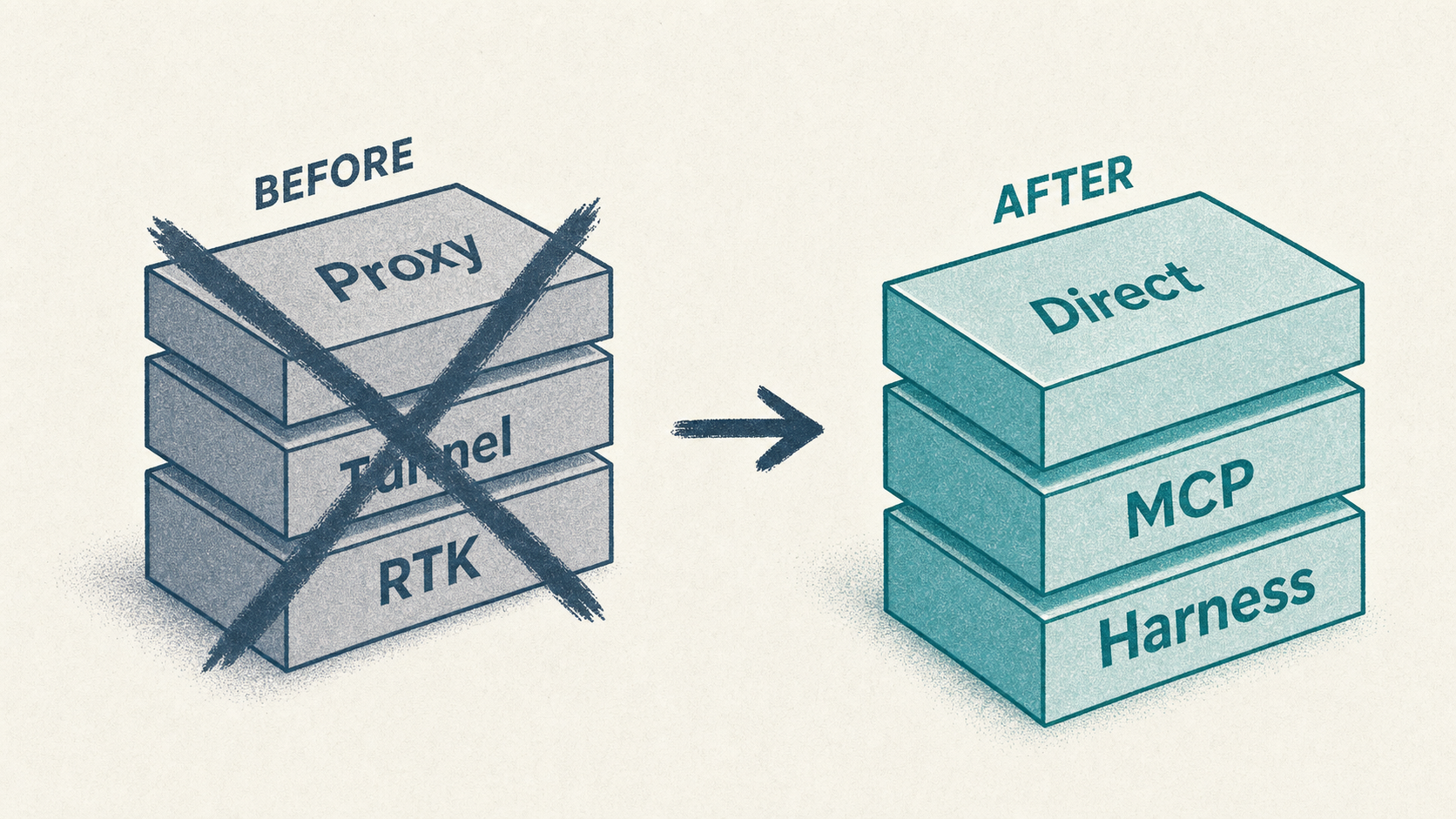
TL;DR
- I ran Headroom, built a 300-line proxy, wired a Cloudflare tunnel, and added RTK.
- On my Cursor + OpenRouter workload the dollars did not move.
- Here is what is worth doing instead.
Cost context: GitHub Copilot vs OpenRouter pricing
Workflow context: Copilot → Cursor migration
What replaced the proxy: Lightweight agent harness (Part 1) · Four-tier memory
What is Cursor token saving beyond proxies?
Cursor token saving on OpenRouter-heavy workloads is mostly input discipline, cache shape, harness gates, and model choice—not a local HTTP proxy compressing an already-cached prompt stream.
Who it is for: practice leads and program directors managing Cursor Agent volume and OpenRouter spend who tried Headroom, tunnel, or RTK and want an honest post-mortem before installing more middleware.
What you will learn: which savings layers stack orthogonally, measured numbers from one production experiment (proxy retired July 2026), and what to run instead (direct OpenRouter, Context7, Serena, harness policy).
The problem: I wanted cheaper Cursor chats without changing how I work
Cursor bills through token volume. Compression proxies, shell filters, and cache tricks all promise 30% to 95% savings without touching your prompts. I tried that stack for real production work on a Shopify-style web app (React Router 7, hosted API, OpenRouter, and an OpenRouter model in a region where several frontier APIs are region-blocked).
As of July 2026 I turned it all off. The proxy scheduled tasks are disabled. The named Cloudflare tunnel hostname is decommissioned (DNS should not point at my machine; do not probe old URLs from superseded drafts). Cursor runs direct OpenRouter. The monthly dollar delta was negligible. Worse: running traffic through my proxy lowered OpenRouter prompt-cache hit rate (about 90%+ direct vs about 80% through the proxy).
This post is the digest: what I tried, what savings are actually realizable, why the experiment failed, what I learned, and what I run now (Context7, Serena, harness policy, four-tier memory).
Why this matters before you install anything
Token-saving tools are orthogonal layers. They stack only when each layer attacks a different part of the bill:
| Layer | What it shrinks | Typical tools |
|---|---|---|
| Source | What the agent reads or runs | Serena, Context7, LeanCTX, ripgrep aliases |
| Path | Bytes on the wire to the model | Proxy postprocessor, RTK, Tamp |
| Cache | Repeated prompt prefixes | OpenRouter native cache, cache_control |
| Model | Price per token | Composer 2.5 baseline, routing |
| Session | Context bloat across turns | Rules, harness gates, footer contract |
| Tooling | Shell output noise | RTK, jq/rg/fd instead of cat/grep/find |
If your bill is mostly completion tokens and long chat history, a proxy that only tweaks the prompt stream will not move the needle. If OpenRouter already caches your prefixes, adding cache_control injection in front can change request shape and hurt cache keys. That is what happened here.
What I tried (timeline)
| Phase | What | Goal |
|---|---|---|
| 1 | Headroom proxy on a local port | HTTP-layer compression |
| 2 | Custom Token Optimizer proxy (proxy.py, ~300 lines) on a second local port | Five small layers instead of Headroom ML |
| 3 | Cloudflare named tunnel (e.g. https://cursor-proxy.example.dev/v1 — use your hostname) | Bypass Cursor SSRF so chat could reach localhost |
| 4 | RTK preToolUse hook | Compress shell output before the model sees it |
| 5 | A/B harness (60 calls, fresh OpenRouter keys) | Measure proxy on vs off |
| 6 | Retired proxy, tunnel, RTK, Headroom MCP | Direct OpenRouter + MCP input discipline |
Headroom on my traffic (90-minute test, 37 requests): 5.7% average compression (from internal session tracking). Below the 30% bar I set before the test. The advertised cache hit path did not match OpenRouter-shaped traffic.
Token Optimizer looked better in smoke tests (prompt-cache markers, 1 ms local repeat hits, RTK on git status). Real dashboard math did not hold up once I counted OpenRouter Activity and cache hit % with the proxy in path.
What I measured (honest numbers)
| Signal | Result |
|---|---|
| A/B harness (tiny prompts, fresh keys) | Proxy +4.7% on chat-shaped calls; OFF cohort sometimes higher cache % |
| RTK telemetry | 34.8% compression on git status — but only ~464 tokens across four shell runs |
| OpenRouter cache hit | ~80% with proxy vs ~90%+ direct (−10 percentage points) |
| Monthly spend (proxy key) | ~$8 on ~75M tokens — savings dominated by OpenRouter's own prompt cache, not my layers |
| Tunnel + scheduled tasks | Worked when live; infra cost (reboots, ACLs, wrong proxy.py path for weeks) with no dollar payoff |
Benchmark claims from tool READMEs (Headroom 60–95%, LeanCTX 88% sessions, RTK 30–80% shell) are workload-dependent. My workload is chat-heavy Cursor Agent, not file-read-heavy Claude Code sessions. Shell output was a small slice of total tokens.
Additional detail
Why the experiment failed (for my workload)
- OpenRouter already caches. My proxy injected
cache_controland headers. That may have disturbed cache keys. Net: lower hit rate, not higher savings. - RTK volume was tiny. Chat sessions burn tokens on prompts and completions, not
git statusoutput. - Local LRU only helps byte-identical repeats. Multi-turn conversations rarely repeat the full body.
- Completion tokens dominate on agentic work. The proxy barely touched output except optional caps.
- Complexity tax. Two scheduled tasks, tunnel config, duplicated
proxy.pypaths, SSRF workarounds. Maintenance without ROI. - Headroom mismatch was structural, not tuning: ML compression stage on a stream OpenRouter was already caching upstream.
The tunnel pattern is still useful if you must expose localhost to Cursor (SSRF blocks private IPs and localhost). Use a hostname you control, protect the proxy (auth, bind to loopback only), and delete the DNS record when you retire the stack. I no longer route chat through a local proxy.
What savings are actually realizable (what I believe now)
| Approach | Worth it on my stack? | Notes |
|---|---|---|
| Direct OpenRouter + native prompt cache | Yes — default | Clear Cursor base URL override; watch Activity dashboard |
| Context7 (framework docs) | Yes — main app repos | Stops wrong-guess refactors that burn retry tokens |
| Serena (symbols, not full files) | Yes — large repos | Input reduction at source layer |
| Harness policy (when to batch / test / skip bootstrap) | Yes | See harness series |
| Four-tier memory + footer contract | Yes | External Memory series; Layer 4 = feedback loop |
| Composer 2.5 baseline | Yes | Predictable rule compliance |
| RTK / shell aliases | Maybe if shell-heavy | Low cost; I removed RTK when proxy retired |
| Proxy + tunnel | No for me | Only reconsider for tool-output-heavy, exact-repeat workloads |
| Headroom | No for my traffic | 5.7% measured; high CPU on Kompress path |
| LeanCTX | Deferred | Overlaps Serena; validate on a pilot repo first |
Power stays with you: model dropdown, Plan vs Agent, ship approval. The harness and memory stack support procedure (when to load brain-pack, when to run tests). They do not auto-switch models or override your choices.
What I run now (July 2026)
Cursor → direct OpenRouter (no base URL override)MCP: Context7 + Serena (+ optional context-mode on the busiest repo)Rules: context-budget.mdc + HARNESS-POLICY routing tableMemory: four tiers (L4 feedback = session footer + rules + eval:gate)Metering: OpenRouter Activity + quarterly ghost-token auditLab: Tokensaver repo keeps A/B harness + archived dashboardsNext reads in order:
- Agent harness without a microservice — you keep controls; policy routes subagents and tests
- Harness memory loop (four tiers) — when to load operational vs evergreen vs feedback
- Measure the harness — CSV, CI, dollars before building more orchestration
Proxy source and dashboards are archived in a local lab repo (proxy.py, dashboards/legacy/). Not maintained as production infra.
Additional detail
What I would do from zero today
- Meter first. OpenRouter Activity for one week on direct routing. Know cache hit % and completion share before adding middleware.
- Input discipline. Context7 before framework guesses; Serena before full-file reads.
- Session contract. Four-tier memory with footer v3.1 at ship time.
- Harness policy. One-page table: direct vs batch vs test. No microservice until CSV proves a gap.
- Shell aliases (1 hour) if agents run noisy commands daily.
- Proxy/tunnel last — only if measurement shows tool-output or exact-repeat dominates and direct cache is already maxed.
Reference
Quick reference: token-saving layers
| Layer | What it shrinks | Example tools | Worth it on chat-heavy Agent? |
|---|---|---|---|
| Source | What the agent reads | Context7, Serena, ripgrep | Yes |
| Path | Bytes on the wire | Proxy, RTK, Tamp | Often no if OpenRouter already caches |
| Cache | Repeated prefixes | OpenRouter native cache | Yes — default direct |
| Model | Price per token | Composer 2.5 baseline | Yes |
| Session | Context bloat | Rules, harness gates, footer | Yes |
| Tooling | Shell output noise | RTK, jq/rg | Maybe if shell-heavy |
Example stack (July 2026): Cursor → direct OpenRouter · MCP Context7 + Serena · context-budget.mdc + HARNESS-POLICY · four-tier memory · OpenRouter Activity dashboard.
Common mistakes
| Mistake | Why it fails | Fix |
|---|---|---|
| Installing proxy before metering direct | Cannot see cache hit % baseline | One week OpenRouter Activity on direct routing |
| Trusting README compression % on different workload | Headroom 60–95% ≠ chat-heavy Cursor | A/B on your traffic; retire if cache hit drops |
| RTK for chat-heavy sessions | Shell output is tiny slice of bill | Match layer to dominant token source |
Proxy injecting cache_control upstream | May disturb OpenRouter cache keys | Compare hit % direct vs proxied |
| Skipping harness while chasing compression | Subagents paste 42k history | Policy table + memory gates (harness series) |
| Keeping tunnel infra after proxy retired | Reboots, ACLs, DNS with no dollar payoff | Decommission hostname; point Cursor at direct API |
FAQ
Did the proxy save any money?
Not meaningfully on my workload: ~$8 on ~75M tokens dominated by OpenRouter's own prompt cache; proxy lowered cache hit ~10 percentage points.
When is a local proxy still rational?
When tool-output or byte-identical repeats dominate the bill and direct cache is already maxed—rare for chat-heavy Agent loops.
What fixed SSRF without fixing savings?
A public HTTPS tunnel lets Cursor reach localhost; it solves routing, not unit economics. I retired that tunnel stack; see the SSRF note above.
What should I install first?
Meter direct OpenRouter → Context7/Serena input discipline → harness policy → four-tier memory. Proxy/tunnel last.
Is Headroom wrong for everyone?
No. It targets large repeated boilerplate in huge contexts. My Cursor + OpenRouter chats peaked ~8–12K tokens with varying turns—workload mismatch, not necessarily a bad product.
Reader action
- If you run a local proxy today: compare OpenRouter cache hit % direct vs through proxy. If hit rate drops, the proxy is costing money.
- If you see
Access to private networks is forbidden: that is Cursor SSRF, not OpenRouter. A public HTTPS tunnel fixes routing; it does not fix savings by itself. - If you want sustainable savings: start with direct routing, MCP input tools, and harness gates. Read Part 1 of the harness series.
If you're new to Cursor: 50% off your first month (code
JP5ARNKSFI2Q). I may earn usage credits; install directly if you prefer.
Get practical posts on enterprise AI and transformation. Only useful updates, sent as a weekly digest.
One practical digest each week. Unsubscribe anytime.


