TL;DR
- A practical breakdown of how Gravio turns repository signals into six-dimension scores, hard quality gates, and actionable remediation plans.
Gravio’s scoring engine was built to solve one hard problem: teams using AI-assisted development needed a repeatable way to tell whether code quality was improving or quietly drifting.
Most teams already had tests, linting, and a few ad hoc checks, but those checks were fragmented and not comparable across projects. We needed one system that could read real repository state, score quality dimensions consistently, and block risky releases with explicit gate policy.
Why this mattered
Without a unified score, quality discussions stayed subjective. A project could pass unit tests while still failing on secrets hygiene, adversarial eval coverage, or operational observability.
That gap is expensive in practice. Regressions surface late, security mistakes are discovered in production, and teams spend review time arguing about severity instead of acting on agreed thresholds.
The design goal was straightforward: convert noisy engineering reality into a transparent quality model that drives decisions, not dashboards.
What was actually happening in the codebase
Gravio had two simultaneous constraints. First, it needed to score diverse ecosystems with one rubric. Second, it had to avoid requiring heavyweight framework lock-in just to be scorable.
That pushed us toward signal detection rather than framework coupling. Instead of requiring one eval tool, one CI provider, or one language stack, the scanner inspects repository evidence: files, configs, scripts, and dependency hints.
In other words, Gravio asks, “What is truly present and enforced in this repo?” not “Did you adopt our preferred stack?”
The architecture we chose
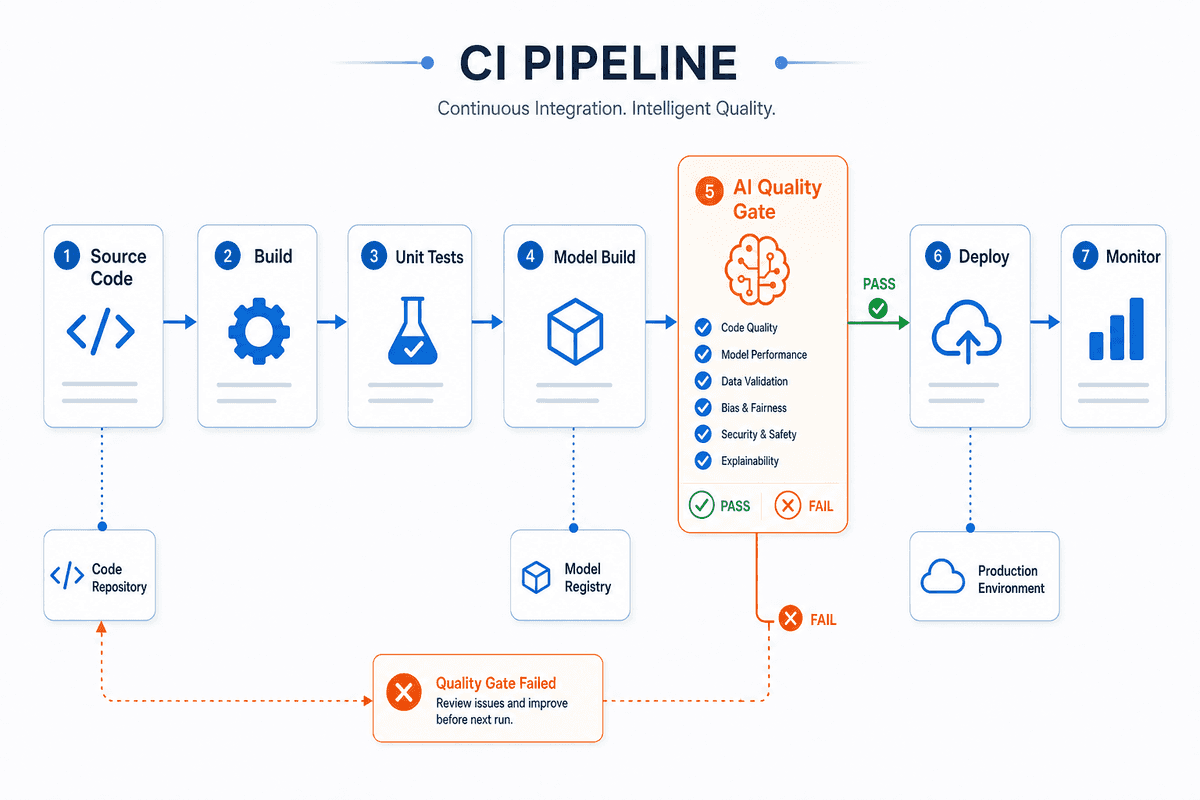
The scoring system is implemented as a pipeline with four stages:
- Detect quality signals from the repository.
- Map those signals to workflow pass/fail evidence.
- Compute six dimension scores and one weighted overall score.
- Apply release gate policy and emit remediation guidance.
This keeps each layer explainable. If a score drops, you can trace it back to a specific missing signal or failed workflow, not a black-box model judgment.
Stage 1: Signal detection
The scanner reads repository structure and metadata to produce a normalized scan object. It looks for concrete indicators such as test files, CI workflows, lockfiles, secret scanning setup, eval directories, baseline artifacts, monitoring configs, and agent instruction files.
For evaluation coverage specifically, Gravio checks for eval-oriented directories and configs, including patterns like evals, benchmarks, and evaluation frameworks detected via dependency/config fingerprints.
A key tradeoff here was breadth versus false positives. We intentionally detect broad evidence classes so mixed stacks can be scored, then reduce ambiguity later through workflow evidence and gate checks.
Stage 2: Workflow evidence mapping
Raw signals are not yet a quality judgment. Gravio maps signals into workflow results with explicit status and evidence payloads.
Each workflow has an id, category, critical flag, and required evidence shape. Examples include secret scan hygiene, eval suite presence, baseline tracking, adversarial tests, and trace capture.
Critical workflows are treated differently from advisory workflows. A non-critical failure may lower scores and trigger recommendations, while a critical failure can block gate pass directly.
This layer gave us a major implementation benefit: new policy checks can be added without rewriting score math.
Additional detail
Stage 3: Six-dimension scoring
Gravio computes six scores from 0 to 100:
- safety
- reliability
- evaluation
- observability
- governance
- agentic
Each dimension is additive and capped at 100. For example, evaluation score increases when the repo shows eval corpus/config presence, baseline tracking, golden datasets, runnable eval scripts, adversarial coverage, and prompt tests.
The overall score is a weighted average:
overall = safety×0.25 + reliability×0.20 + evaluation×0.15 + observability×0.10 + governance×0.15 + agentic×0.15
These weights were chosen to prioritize failure impact. Safety and reliability carry more weight because their regressions usually have higher blast radius than presentation or convenience concerns.
Stage 4: Gate policy and release decision
Scoring alone is not enough; teams need pass/fail policy that matches shipping risk. Gravio applies threshold gates against each run.
Baseline gate values include:
- minimum overall score: 87
- minimum workflow pass rate: 90%
- minimum safety score: 90
- maximum critical adversarial failures: 0
- maximum allowed overall regression from previous run: 2 points
The gate can fail even when overall score looks acceptable if critical workflow conditions are violated. That was intentional: high-level averages should never hide hard safety or adversarial failures.
Why we built both scorecard math and workflow gates
A pure score system is easy to game. Teams can optimize dimensions with many easy wins while ignoring critical blockers.
A pure gate system is too binary for continuous improvement. Teams need to see trend direction and partial progress, not only pass/fail.
Combining both solved this. The scorecard supports prioritization and trend analysis, while gate checks enforce non-negotiable release constraints.
Additional detail
How recommendations are generated
When workflows fail or dimension gaps are large, Gravio builds action plans tied to those exact failures. Recommendations are not generic tips; they carry priority, rationale, suggested commands, and completion conditions.
This made the system much more useful in real teams. A score without an action path creates reporting overhead. A score with concrete remediation becomes an execution tool.
What changed after implementation
The engine created three immediate improvements in workflow quality:
-
Quality became discussable with shared terms. Teams stopped debating vague quality impressions and started reviewing evidence-backed deltas.
-
Regression risk became visible earlier. The baseline comparison and gate thresholds exposed drift before release rather than after incidents.
-
AI-assisted development got safer defaults. Agentic and governance checks ensured that AI usage quality was measured as an operational discipline, not a side note.
Real tradeoffs and limitations
No scoring engine is neutral. Ours reflects deliberate policy choices.
First, signal-based detection can produce edge-case ambiguity in unusual repo layouts. We accepted that because portability across ecosystems was more valuable than perfect stack-specific precision.
Second, weights and thresholds are opinionated. They are calibrated for broad engineering risk, not every organization’s local context. Teams should tune policy where business risk differs.
Third, some advanced quality properties still need human judgment. The engine can detect structure and guardrails reliably, but architecture quality and product correctness still require review.
Final solution
The final Gravio scoring engine is a layered, explainable quality system:
- a repository signal scanner
- a workflow evidence mapper with criticality
- a six-dimension weighted scorecard
- a hard gate policy for release decisions
- a recommendation layer that turns failures into concrete next actions
That architecture keeps the system practical. It works across stacks, resists vanity scoring, and gives teams a usable bridge from measurement to remediation.
What is the Gravio scoring engine?
The Gravio scoring engine is a layered quality pipeline that turns repository signals into six dimension scores (safety, reliability, evaluation, observability, governance, agentic), a weighted overall score, hard release gates, and remediation recommendations. It asks what evidence is truly present in the repo—not whether you adopted a preferred stack.
Reference
Quick reference: six dimensions and weights
| Dimension | Weight | Examples of evidence |
|---|---|---|
| Safety | 25% | Secret scanning, adversarial tests |
| Reliability | 20% | Tests, CI, lockfiles |
| Evaluation | 15% | Eval corpus, baselines, golden sets |
| Observability | 10% | Monitoring, trace capture |
| Governance | 15% | Policy files, review discipline |
| Agentic | 15% | Agent instruction files, guardrails |
Overall = weighted average. Gates can fail independently (e.g. critical adversarial failures, regression limits).
Common mistakes (interpreting Gravio scores)
| Mistake | Symptom | Fix |
|---|---|---|
| Optimizing average score only | Critical blockers hidden | Check gate failures separately |
| Treating score as vanity metric | No remediation action | Use recommendation layer per failure |
| Ignoring dimension regressions | Overall looks fine | Review category deltas and workflows |
| Expecting stack-specific precision everywhere | Edge-case ambiguity | Tune policy for local risk profile |
| Skipping baselines | No regression detection | Store runs; enforce delta limits |
FAQ
Why both scorecard math and workflow gates?
Pure scores are gameable; pure gates are too binary for improvement. Combined: scores prioritize work; gates enforce non-negotiable release constraints.
What are baseline gate values?
Examples include minimum overall 87, workflow pass rate 90%, safety 90, zero critical adversarial failures, max 2-point regression from previous run—tunable per org.
How are recommendations generated?
From exact workflow failures—priority, rationale, suggested commands, and done conditions—not generic tips.
Can unusual repo layouts affect detection?
Yes—signal-based detection trades perfect stack precision for portability across ecosystems. Tune policy where business risk differs.
What should I build if rolling my own engine?
Define risk-tied dimensions, separate evidence from scoring math, add critical gates independent of average, store baselines, attach action paths to every failure.
What you can apply next
If you are building your own quality engine, start with this sequence:
- Define a small set of dimensions tied to shipping risk, not vanity metrics.
- Separate evidence collection from scoring math.
- Add critical workflow gates that can fail independently of average score.
- Store baselines and enforce regression limits.
- Attach every failed check to an action path with clear done conditions.
If your current setup is dashboard-heavy but decision-light, this model is a practical upgrade path. For a related architecture perspective on reducing operational noise in product systems, see /posts/why-i-rebuilt-petralian-on-nextjs.
Get practical posts on enterprise AI and transformation. Only useful updates, sent as a weekly digest.
One practical digest each week. Unsubscribe anytime.