TL;DR
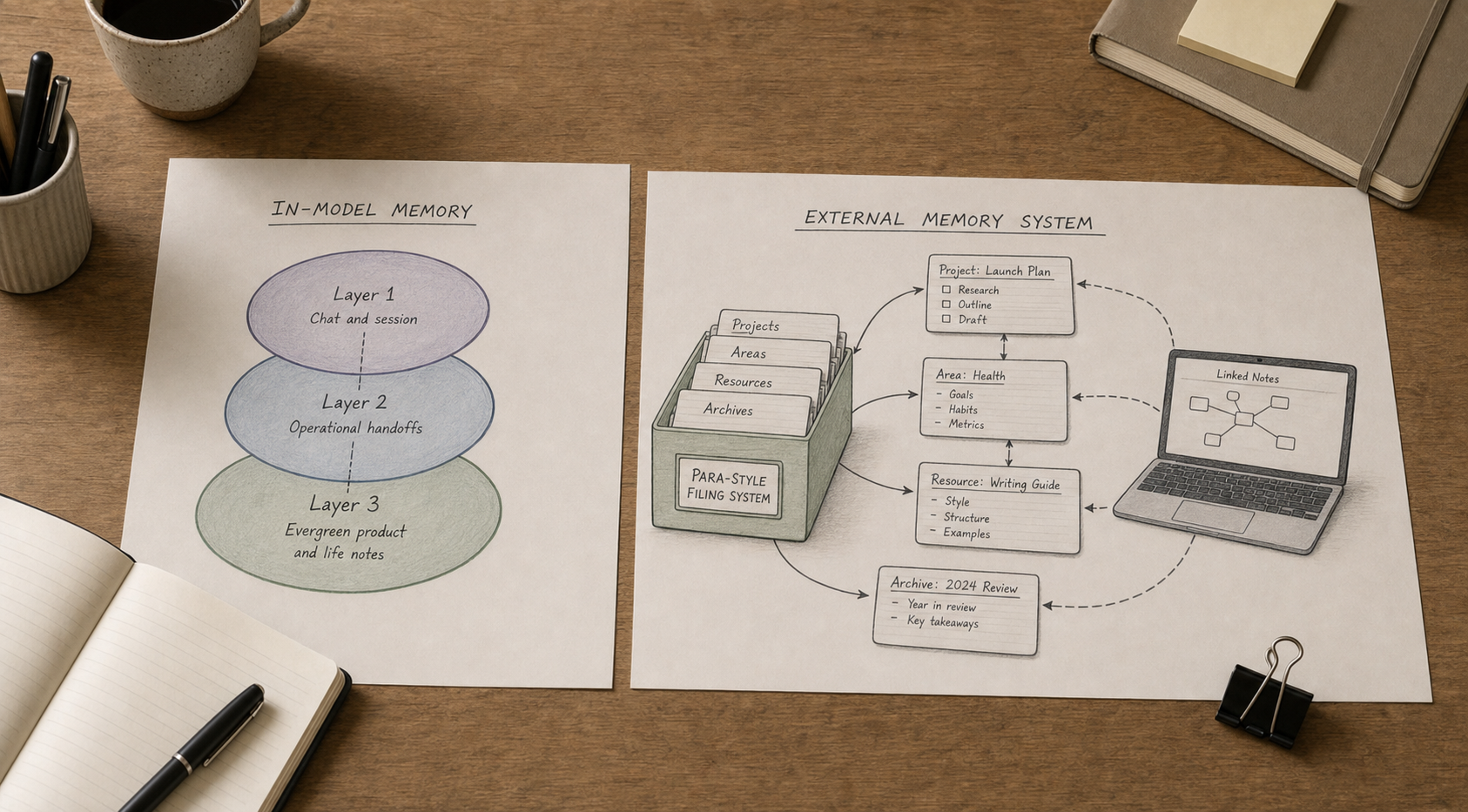
- The popular STM / LTM / feedback diagram optimizes in-model memory.
- A file-based external brain optimizes audit, handoff, and tool churn.
- Here is when each design wins—and why I chose files.
External Memory Series (3 of 4) — Series hub · 1 Implementation · 2 Productivity · 3 vs the diagram (this article) · 4 Governance
Read first if you are new: The AI Memory Problem on petralian.com/posts
The three-layer AI memory diagram is everywhere: short-term memory, long-term memory, feedback loops. It is a useful teaching picture. It is also easy to misread as a product requirement—"my stack should look like this inside the model."
I run production software with AI as the primary implementer. My memory system does not live mainly in the context window. It lives in Obsidian, repo handoff files, rules, and hooks. When I scored that setup against the diagram, I got roughly 70% conceptual overlap and 40% structural match. That sounds like a partial implementation. It is not. It is a different design that wins on different criteria.
This article answers four questions plainly: Is the file-based design better? Different? Worse? And why—for builders shipping real software, not for vendors selling native memory features.
What is file-based AI memory vs the three-layer diagram?
The three-layer diagram (short-term memory, long-term memory, feedback) describes memory inside an agent runtime—attention, retrieval, and product-side learning. File-based external memory stores operational handoffs, evergreen product notes, and enforceable rules in Markdown and git that you own, diff, and port across tools.
Who it is for: program owners and practice leads comparing in-chat or in-product memory to a deliberate external brain before committing to a stack.
What you will learn: When each architecture wins, five reasons files win for production work, honest tradeoffs, and a one-table decision guide. Implementation detail is in Part 1; the series hub maps the full series.
The problem the diagram solves vs the problem I had
The diagram describes memory inside an agent runtime:
| Layer | Typical meaning |
|---|---|
| Short-term | Current conversation, limited capacity, overwrite by default |
| Long-term | Patterns and facts that persist across sessions |
| Feedback | User corrections reinforce or discard what is stored |
That model fits assistants whose business is "we remember you"—long context, retrieval, profile memory, product-side learning.
My problem was different:
- Resume Monday without re-explaining deploy state and open loops.
- Govern what an agent must never do again (platform auth, extension limits, CI invariants).
- Audit why we shipped a change when a merchant reports a bug.
- Survive switching between Claude, ChatGPT, IDE agents, and future models without re-onboarding the tacit layer.
None of those are solved by a bigger context window alone. They need durable, inspectable stores outside the chat. That is the problem file memory solves.
Why the distinction matters
If you treat low "structural match" to the diagram as a failing grade, you optimize for the wrong target—you add chat summarization and hope the model "remembers," while production still lacks a handoff surface, decision trail, or commit-linked product notes.
If you treat file memory as better for builder outcomes, you invest in:
- Operational handoffs (session summaries, bridge notes,
NEXT_SESSION.md) - Evergreen product truth (
Features/*.md, architecture notes) - Feedback that writes rules (agent instructions, gotchas, git hooks)
The trade is real: more setup, more discipline. The return is memory you own, diff, and move across tools.
What is actually happening: two architectures
Architecture A — In-model (diagram-default)
Memory is opaque to you. Audit means scrolling threads. Tool change often means reset.
Architecture B — External files (my setup)
Memory is Markdown, git, and scripts. Audit means files and hashes. Tool change means the same bootstrap paths.
I also run a fourth tier the diagram does not show: feedback hardened—session end footers, post-commit Feature note updates, deploy lock scripts, custom agents that only write handoffs or releases. That tier is why feedback is stronger in practice than "the user corrected the model in chat."
Five reasons file memory wins (for production builders)
Use this as the scannable version of the argument. The sections below unpack each point.
1. You separated “resume work” from “know the product”
The diagram collapses “remember last time” into long-term memory. I split:
| Tier | What it holds | Examples |
|---|---|---|
| Operational | Resume next session | Bridge, Summaries, NEXT_SESSION.md, dated session notes |
| Evergreen | Know the product | Features/*.md, Architecture/*, 00_Brain |
That matches how real work breaks down. Monday needs “what’s open and what deploy state.” Refactoring needs “what the scoring module must never do.” One blob of “long-term memory” mixes those jobs and makes bootstrap either noisy or shallow.
2. Feedback is enforceable, not implied
Diagram feedback: reinforce good, discard bad—usually meaning the model or product learns inside the runtime.
File feedback: Session End footer, self-improvements must cite a file path, rules in agent instructions, hooks at session start and post-commit.
That is governance: lessons become diffable artifacts. Chat-only feedback dies in the thread; this design makes “we learned” verifiable.
3. It survives tool and model churn
STM/LTM in the diagram are tied to one runtime. My long-term store is Markdown on disk plus git. Claude today, another chat product tomorrow, a different IDE agent next quarter—the bootstrap order and Obsidian graph stay.
For anyone shipping client-grade software with AI, that portability is a feature the diagram does not address.
4. Audit and handoff are first-class
Clients, future you, and incident review need: what we decided, what shipped, why.
Chat memory is weak for that. A deliberate chain is not:
Feature note → ## Commits (from git hook) → session summary → health/inbox snapshot → deploy footer in the session note.
Each link is a file or hash you can open without scrolling a thread. The diagram does not optimize for accountability; file memory does.
5. Automation at boundaries—not inside attention
session-start scripts, IDE session hooks, post-commit → Feature notes—these are the diagram’s missing short-term → durable transfer, implemented where transfer is reliable (session open, git commit), not inside attention weights.
That is a pragmatic upgrade over “hope the agent updates the note.” Details in part 1 of this series.
Additional detail
Is it better?
Yes—for sustained AI-first product work. Not universally.
| Outcome | In-model diagram ideal | File-based design |
|---|---|---|
| Resume after days away | Depends on product memory | Strong (Bridge, Summaries, NEXT_SESSION) |
| Audit ("why did we ship?") | Weak | Strong (commits → Feature notes, footers) |
| Tool / model churn | Weak | Strong (vault on disk) |
| Team or future-you handoff | Weak | Strong (hub notes, links) |
| Compounding lessons | Medium | Strong (rules with file citations) |
| Setup effort | Low | Higher |
| Small prototype | Fine | Often overkill |
| "Feels automatic" | Higher | Lower unless hooks run |
Better here means fit for production builders, not "better for every user of ChatGPT."
Concrete mechanisms from open-source reference stacks (Gravio, petralian.com, May 2026):
- IDE
sessionStarthook +session-start.ps1→ bootstrap snapshot post-commithook →Features/*.md## Commitsfromfeature-note-map.json- Dual vault:
00_Brain(how to work) + project vault (what the product is) - Session End footer: deploy state, rollback tag, self-improvements must cite a file path
Those are builder outcomes the diagram does not specify.
Is it different?
Yes—by design, not accident. This is not “diagram + extras.” It is a different target.
| Diagram | File-based design |
|---|---|
| Memory inside the agent | Memory outside the agent (you own the files) |
| One long-term bucket | Operational + evergreen + rules |
| Feedback adjusts internal state | Feedback writes files and hooks |
| Attention as filter | Bootstrap order + hub notes as filter |
| Single product / session | 00_Brain (cross-project) + per-project vault |
My setup is a documentation-centric external brain—Zettelkasten-style evergreen notes plus a session loop—not a neural memory stack. ~40% structural match to the infographic is expected; ~70% conceptual overlap (session context, durable store, feedback) is real. The implementation plane is what diverges.
Is it worse? (five honest tradeoffs)
Sometimes yes. Not because files are wrong—because the job or your discipline does not justify the cost.
1. Higher upfront and ongoing cost.
Diagram-style product memory is passive for the user (“it remembers me”). File memory requires session-close discipline, promotion rules, and map maintenance. If you will not maintain files—session end never runs, Feature notes rot—file memory is worse than a long-context chat: you paid complexity without discipline, and chat degrades more gently.
2. The scope is small.
A weekend script or a one-file tool does not need four tiers, dual vaults, and deploy footers. For that, file memory is heavy. For a long-lived, multi-module product (the scale of Gravio or petralian.com), the complexity is appropriate. Diagram-style “good enough in thread” wins on simplicity.
3. Duplication and drift.
NOTES.md vs Obsidian vs memories/repo/ can disagree. The diagram has one LTM; you may have mirrors for speed (repo) and readability (Obsidian). That is a consistency problem you chose on purpose—fixable with single-source-of-truth rules, not a fatal flaw.
4. Execution is not automatic.
~70% conceptual overlap still leaves promotion on protocol and hooks, not on the model “deciding what matters.” Miss session end → gaps. Native memory products bet on automation inside the product; file memory bets on inspectable process.
5. Platform quirks (known weak spot).
IDE session-start injection can drop on some builds. The fix—a snapshot file on disk plus an always-on rule—is deliberate resilience: design acknowledging platform limits, not weakness of the model itself.
Additional detail
Why I chose files (the reasoning, not the slogan)
Inspectability beats opacity
When memory is only chat, you cannot answer: "What did the agent believe about billing on May 14?" When memory includes Features/Billing and Plans.md and a commit line - \f1c5761` (2026-05-15) — …`, you can.
For client work and incident response, inspectability is not pedantry. It is risk management.
Handoff is a first-class object
The diagram merges "remember last time" into long-term memory. I split operational memory (what is open this week) from evergreen memory (what the product is). That split matches how work actually resumes: different questions, different files.
Feedback should leave artifacts
Chat feedback: "No, use Remix Form not native form."
File feedback: new bullet in known-gotchas.md + line in your agent instructions file cited in the session footer.
The second prevents the class of error. The first fixes one instance. My footer rule—no vague "lesson recorded"; cite path and line—exists because undocumented feedback is fiction.
Tool churn is a when, not an if
Models and IDEs change quarterly. Files in Obsidian and git do not require retraining or export. The memory landscape piece argues tool-agnostic knowledge wins long-term; file memory is how a builder implements that bet.
When to use which mental model
Start here if you only read one table in this article.
| What are you building? | Better fit |
|---|---|
| Long-lived product — many sessions, handoff, compliance, or “why did we ship this?” | File layers + hooks (this series) |
| Quick prototype — few sessions, exploratory chat, acceptable amnesia between projects | Diagram-style chat memory — often enough |
Prefer the file stack when: production app, solo builder + agents, multiple tools (Claude, ChatGPT, IDE agents), need to resume weeks later, need an audit trail.
Prefer diagram-native / in-product memory when: exploratory chat, personal assistant inside one product, minimal setup, you will not maintain files.
Comparison chart: when each design wins (expanded)
| Scenario | Prefer in-model / diagram | Prefer file-based external brain |
|---|---|---|
| Explore an idea for 20 minutes | ✓ | |
| Ship and maintain app for 12+ months | ✓ | |
| Single tool, single vendor forever | ✓ (maybe) | |
| Claude + ChatGPT + IDE agents + future tools | ✓ | |
| Need git-linked product memory | ✓ | |
| Need zero setup | ✓ | |
| Compliance / explainability | ✓ | |
| Personal life admin with light AI | Hybrid | ✓ (lighter ops layer) |
How to reduce the "worse" without becoming the diagram
You do not need neural memory to fix drift. You need process:
| Fact type | Canonical home | Mirrors (optional) |
|---|---|---|
| This week's priority | AI Session Bridge / NEXT_SESSION.md | memories/repo/open-loops.md at session end |
| Product behavior | Features/*.md | — |
| Universal workflow | 00_Brain | Stub in project Meta/ |
| Architecture detail | Obsidian Architecture/* | Trim NOTES.md to index only |
| Never again | Agent instructions, known-gotchas.md | — |
Promotion rule in one line: If it matters in 30 days → evergreen; if only next session → bridge; if never → do not write.
Automation belongs at boundaries—session start, git commit—not inside hope that the model promotes notes.
What changed in my stack recently (why this article is "now")
As of May 2026 the reference implementation gained:
memories/repo/— machine-readable handoff mirror (was referenced but missing)scripts/session-start.ps1+ IDEsessionStarthook → bootstrap snapshot on disknpm run hooks:install→ post-commit updates to Feature## Commits- Consistent vault roots across MCP templates and docs (project vault +
00_Brain)
That does not change the philosophy. It lowers the cost of the file-based design—closer to automatic transfer at session open and commit time, without pretending the model has a hippocampus.
Reference
Quick reference
| Question | In-model / diagram default | File-based external brain |
|---|---|---|
| Where does memory live? | Inside agent runtime | Markdown, git, Obsidian, hooks |
| Resume after days away | Product-dependent | Bridge, Summaries, NEXT_SESSION.md |
| Audit ("why did we ship?") | Weak (thread scroll) | Feature notes + commit hooks + footers |
| Tool / model churn | Often resets | Same bootstrap paths on disk |
| Best fit | Quick prototypes, single vendor | Long-lived products, multi-tool workflows |
Verdict shorthand: Better for durable AI-first development; different by design; worse only when scope is small or files won't be maintained.
Common mistakes
| Mistake | Symptom / risk | Fix |
|---|---|---|
| Low structural match → "failing grade" | Optimizing for diagram similarity instead of handoff | Invest in operational layer + evergreen notes, not chat summarization alone |
| Adopting full four-tier stack for a weekend script | Complexity without payoff | Use diagram-style chat for exploratory work; files when sessions span months |
| Collapsing operational and evergreen into one "LTM" | Noisy bootstrap or shallow product truth | Split: Bridge for Monday, Features/*.md for invariants |
| File memory without session-end discipline | Rotting notes; worse than long-context chat | One promotion rule and footer before adding more tiers |
| Treating chat feedback as governance | Same bug class returns | Require file-path citations in session footer; write rules to agent instructions |
FAQ
Is file memory always better than the diagram?
No—for 20-minute exploration or single-vendor personal chat, in-product memory is often enough. Files win for production apps, multi-tool workflows, audit, and resume-after-weeks.
What does "~70% overlap, ~40% structural match" mean?
Same concepts (session context, durable store, feedback), different implementation plane. You added an operational tier and file-based LTM the diagram does not show—that is intentional, not a gap.
Can I combine both approaches?
Yes—hybrid is common. Use product memory for convenience inside one tool; use files for product truth, handoffs, and rules that must survive churn.
When is file memory worse?
Small scope, no maintenance habit, or desire for effortless memory without writing. Honest tradeoffs are in the "Is it worse?" section above.
Where do I implement file memory?
Start with Part 1 for bootstrap order and hooks; Part 4 for audit and governance patterns.
Reader action
Run this one test before adopting either architecture:
- Close all AI tools mid-task on a real codebase.
- Return three days later.
- Count minutes until you are productive.
If you reopen chat and spend twenty minutes reconstructing context, you need operational file memory at minimum—a NEXT_SESSION.md with priority, open loops, and next three steps.
If you are productive in five minutes because one bridge note and a Feature file answered the questions, file memory is working—regardless of how closely your folder structure resembles a diagram.
Then add one boundary automation (session script or commit hook), not a fourth note-taking app.
Bottom line (verdict in one line)
File memory is better than the generic diagram for durable AI-first development; it is different because you optimize for inspectability, handoff, and tool independence—not in-chat recall; it is worse only when the job is small, you will not maintain files, or you want memory to feel effortless without writing.
The three-layer diagram is a good map of in-agent memory. My system is a good map of builder memory—inspectable, linkable, portable, with feedback that edits the system.
Low structural match to the infographic is not a gap to close. It is a sign you optimized for the right opponent: amnesia between sessions, not similarity to a slide.
Related reading
This series: 1 — Implementation · 2 — Personal productivity · 4 — Audit and governance
Published on Petralian: The AI Memory Problem · Your Brain Was Not Built for This · What I Learned Directing AI as My Primary Engineer · Why AI Agent Output Quality Drifts · Getting Enterprise AI Right
Get practical posts on enterprise AI and transformation. Only useful updates, sent as a weekly digest.
One practical digest each week. Unsubscribe anytime.